

1、需求背景
问题场景 (无 Kafka):
1.在大促活动或业务高峰期,成千上万的应用服务器瞬间产生海量日志。
2.Filebeat 将这些日志洪流式地涌向 Logstash。
3.如果 Logstash 处理能力不足,或者后端 Elasticsearch 写入压力大,整个链路就会阻塞。
4.结果:Filebeat 内存堆积,可能丢失数据;Logstash 崩溃;整个日志系统瘫痪。
Kafka 的解决方案:
1.Filebeat 只需将日志快速推送到 Kafka,然后任务就完成了。这个过程非常轻量且快速。
2.Kafka 像一个巨大的缓冲池,可以轻松应对瞬时的高峰流量,将数据“存”起来。
3.Logstash 可以按照自己的处理节奏,从 Kafka 中平稳地拉取数据进行消费。
4.效果:生产者(Filebeat)和消费者(Logstash)完全解耦,互不影响。即使后端处理缓慢,前端数据也不会丢失,实现了完美的“削峰填谷”。
适合场景:
1.大规模、高并发系统
2.关键业务日志
3.复杂数据管道
PS:
如果是业务小,日志缺失也无伤大雅的业务,还是建议filebeat-->es或filebeat-->logstash或logstash-->es即可,会大大减低维护成本
利用已有的ELK环境:ELK实战
2、额外部署kafka4.0
2.1 准备java17环境
下载地址:https://mirrors.tuna.tsinghua.edu.cn/Adoptium/17/jdk/x64/linux/
tar xf OpenJDK17U-jdk_x64_linux_hotspot_17.0.17_10.tar.gz -C /usr/local/
vim /etc/profile,修改完成source /etc/profile
JAVA_HOME=/usr/local/jdk-17.0.17+10
CLASSPATH=$JAVA_HOME/lib/
PATH=$PATH:$JAVA_HOME/bin
export PATH JAVA_HOME CLASSPATH

2.2 下载kafka
wget https://downloads.apache.org/kafka/4.0.0/kafka_2.13-4.0.0.tgz
2.3 解压
tar xf kafka_2.13-4.0.0.tgz -C /data/ && mv /data/kafka_2.13-4.0.0 /data/kafka && cd /data/kafka
2.4 创建uid
KRaft 要求集群有一个唯一的 ID
./bin/kafka-storage.sh random-uuid

2.5 修改日志存储路径
vim config/server.properties

2.6 格式化存储目录
./bin/kafka-storage.sh format -t JX9SuQTWS8KBuvPucWoiig -c ./config/server.properties --standalone
2.7 启动kafaka
./bin/kafka-server-start.sh ./config/server.properties
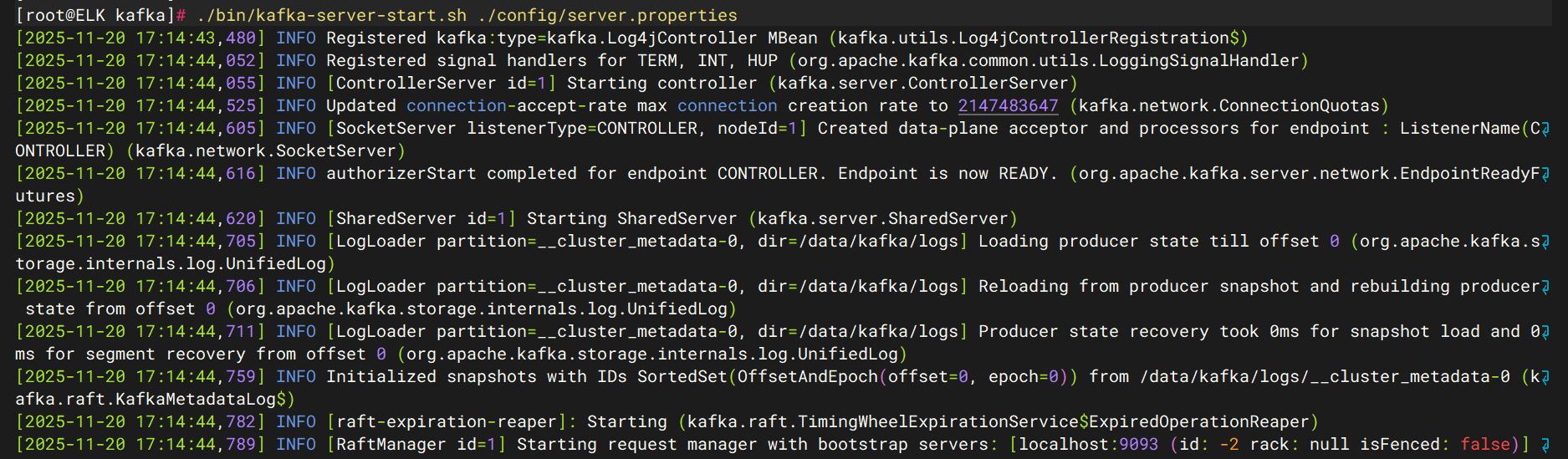
2.8 创建一个日志topic
./bin/kafka-topics.sh --create --topic logs-topic --bootstrap-server localhost:9092 --partitions 1 --replication-factor 1

3、额外部署filebeat
3.1 下载filebeat
wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.10.0-linux-x86_64.tar.gz
3.2 解压
tar xf filebeat-7.10.0-linux-x86_64.tar.gz -C /data && mv /data/filebeat-7.10.0-linux-x86_64 /data/filebeat && cd /data/filebeat
3.3 修改filebeat配置
vim filebeat.yml
#主要以下配置
#日志采集路径
filebeat.inputs:
- type: filestream
enabled: true
paths:
- /root/*.log
#输出到kafka的log-topic
output.kafka:
hosts: ["localhost:9092"]
topic: 'logs-topic'
3.4 启动filebeat
/data/filebeat/filebeat.yml -e &
3.5 检验日志推送到kafka
执行该命令,有打印日志证明filebeat-->kafka成功
./bin/kafka-console-consumer.sh --topic logs-topic --bootstrap-server localhost:9092 --from-beginning

4、修改logstash接收配置
4.1 配置
新增kafka连接方式和日志索引名
input {
kafka {
#kafka连接地址和消费的topic名称
bootstrap_servers => "localhost:9092"
topics => ["logs-topic"]
# 如果日志是 JSON 格式,可以加上这个,否则 Logstash 会把整个消息当作一个字符串
#codec => "json"
}
}
filter {
grok {
match => {
"message" => '%{TIMESTAMP_ISO8601:log_date}\s*\|\s*(?<thread>.*?)\s*\|\s*%{LOGLEVEL:log_level}\s*\|\s*(?<test_id>.*?)\s*\|\s*(?<logger>.*?)\s*\|\s*(?<log_type>.*?)\s*\|\s*(?<host_ip>.*?)\s*\|\s*(?<remote_ip>.*?)\s*\|\s*(?<system>.*?)\s*\|\s*(?<service>.*?)\s*\|\s*(?<request_url>.*?)\s*\|\s*(?<trace_id>.*?)\s*\|\|\s*(?<id>.*?)\s*\|\s*(?<phone_number>.*?)\s*\|\s*(?<device_type>.*?)\s*\|\s*(?<request_status>.*?)\s*\|\s*(?<duration>.*?)\s*\|\s*(?<span_id>.*?)\s*\|\s*%{GREEDYDATA:msg}'
}
tag_on_failure => ["_grokparsefailure"]
}
#增加mutate配置
mutate {
remove_field => ["message", "host"]
}
}
output {
elasticsearch {
hosts => ["http://172.16.10.132:9200"]
#日志索引修改
index => "kafka-logs-%{+YYYY.MM.dd}"
user => "elastic"
password => "xxxx"
}
}
4.2 重启logstash
/data/logstash/bin/logstash -f /data/logstash/config/logstash.conf
重启完成后,会消费kafka推送的日志,es也会生成对应的日志索引

5、Kibana查看日志
5.1 新建kafka-logs*索引
参考:索引模式
5.2 验证
至此,filebeat(采集)-->kafka(生产)-->logstash(消费)-->elasticsearch(存储)--kibana(可视化)已完成。


评论区