

1、elk+filebeat+kafka业务场景
1.1 filebeat配置
filebeat.inputs:
- type: filestream
id: backend-logs #filestream需要唯一id
enabled: true #启用filestream
paths:
- /data/logs/*/*.log #使用通配符采集logs下所有子路径的日志
processors:
#子目录路径核心配置
- dissect: #定义路径的模板
tokenizer: "/data/logs/%{[service_name]}/%{[file_name]}" #解析logs子目录的服务名
# 解析采集日志路径
field: "[log][file][path]" #Filebeat 自动生成的日志文件路径
target_prefix: "" #将解析出的字段添加到事件的根级别
- add_fields:
target: ''
fields:
logs_source: backend #新增值为backend的logs_source字段,区别推送不同topic
- type: filestream
id: nginx-logs #filestream需要唯一id
enabled: true
paths:
- /data/nginx/logs/*.log #nginx采集日志路径
processors:
- add_fields:
target: ''
fields:
logs_source: nginx #新增值为backend的logs_source字段,区别推送不同topic
output.kafka:
hosts: ["localhost:9092"] #kafka实际地址
topic: '%{[logs_source]}-logs-topic' #logs_source变量topic
1.2 kafka配置
#因logs_source有两个变量值,分别是nginx和backend,因此创建nginx-logs-topic和backend-logs-topic两个topic
./bin/kafka-topics.sh --create --topic nginx-logs-topic --bootstrap-server localhost:9092 --partitions 1 --replication-factor 1
./bin/kafka-topics.sh --create --topic backend-logs-topic --bootstrap-server localhost:9092 --partitions 1 --replication-factor 1
1.3 logstash配置
input {
kafka {
bootstrap_servers => "localhost:9092"
##多队列用,分隔,topic名用""引起来
topics => ["nginx-logs-topic","backend-logs-topic"]
####十分关键的字段,从kafka消费的数据json化,否则会读取一些字段失败,如logs_source等
codec => json
}
}
filter {
#判断Logs_source字段,用于不同的grok表达式,这里是nginx
if [logs_source] == "nginx" {
grok {
match => { "message" => '%{GREEDYDATA}' }
}
}
#判断Logs_source字段,用于不同的grok表达式,这里是backend
else if [logs_source] == "backend" {
grok {
match => {
"message" => '%{TIMESTAMP_ISO8601:log_date}\s*\|\s*(?<thread>.*?)\s*\|\s*%{LOGLEVEL:log_level}\s*\|\s*(?<test_id>.*?)\s*\|\s*(?<logger>.*?)\s*\|\s*(?<log_type>.*?)\s*\|\s*(?<host_ip>.*?)\s*\|\s*(?<remote_ip>.*?)\s*\|\s*(?<system>.*?)\s*\|\s*(?<service>.*?)\s*\|\s*(?<request_url>.*?)\s*\|\s*(?<trace_id>.*?)\s*\|\|\s*(?<id>.*?)\s*\|\s*(?<phone_number>.*?)\s*\|\s*(?<device_type>.*?)\s*\|\s*(?<request_status>.*?)\s*\|\s*(?<duration>.*?)\s*\|\s*(?<span_id>.*?)\s*\|\s*%{GREEDYDATA:msg}'
}
}
}
#移除不必要的字段
mutate {
remove_field => ["host"]
}
}
output {
elasticsearch {
hosts => ["http://172.16.10.132:9200"]
#logs_source变量,会根据消费kafka的字段生成对应的索引,如nginx-logs-2025.11.22和backend-logs-2025.11.22
index => "%{logs_source}-logs-%{+YYYY.MM.dd}"
user => "elastic"
password => "xxxxxx"
}
}
1.4 重启filebeat和logstash
/data/filebeat/filebeat -e &
/data/logstash/bin/logstash -f /data/logstash/config/logstash.conf
1.5 检查生成不同日志索引
索引
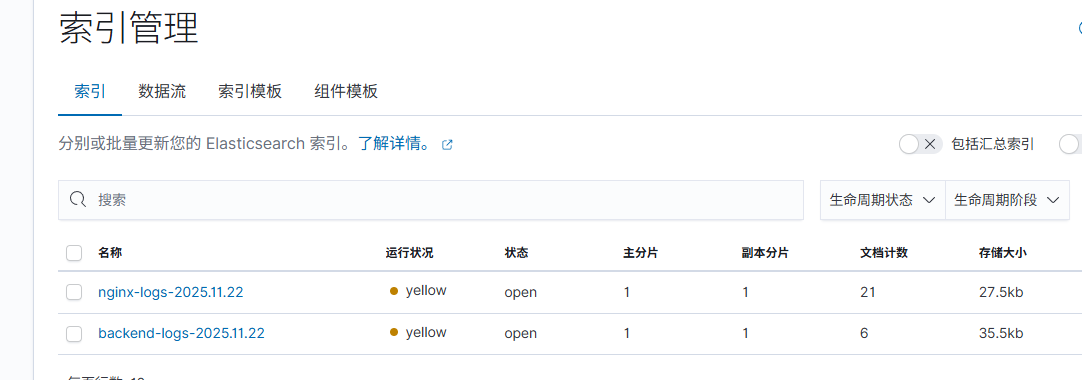
索引模式
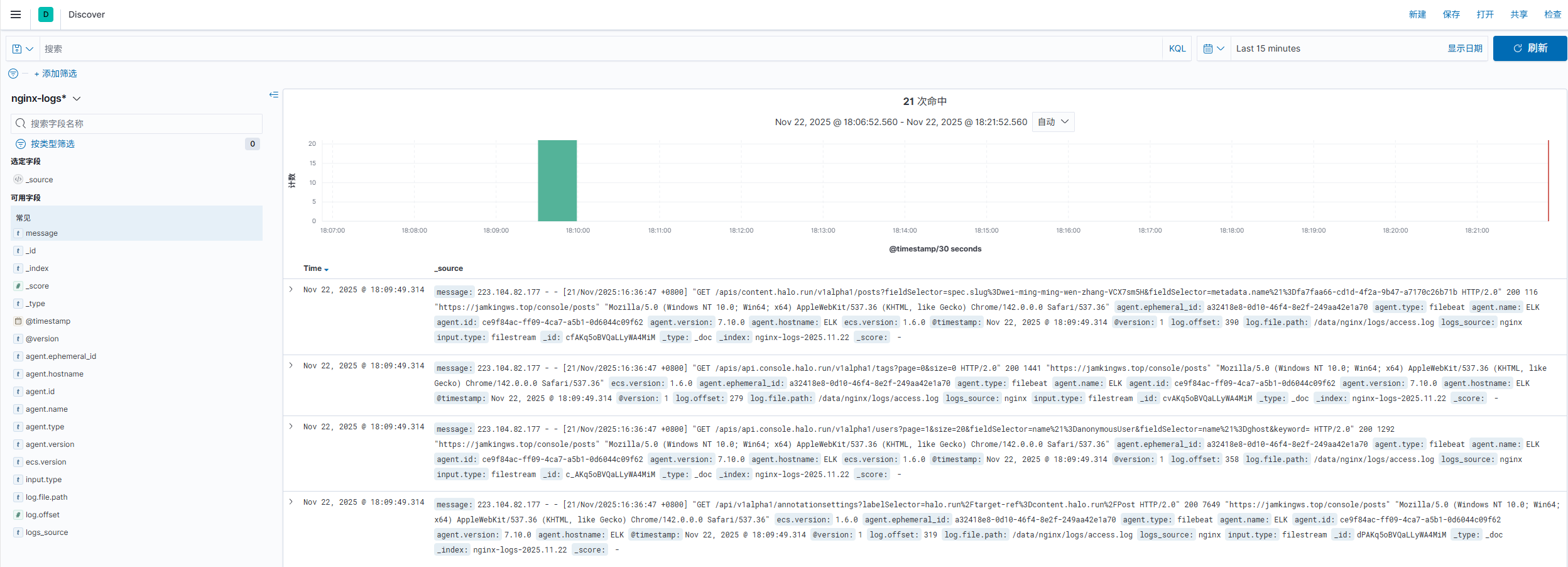
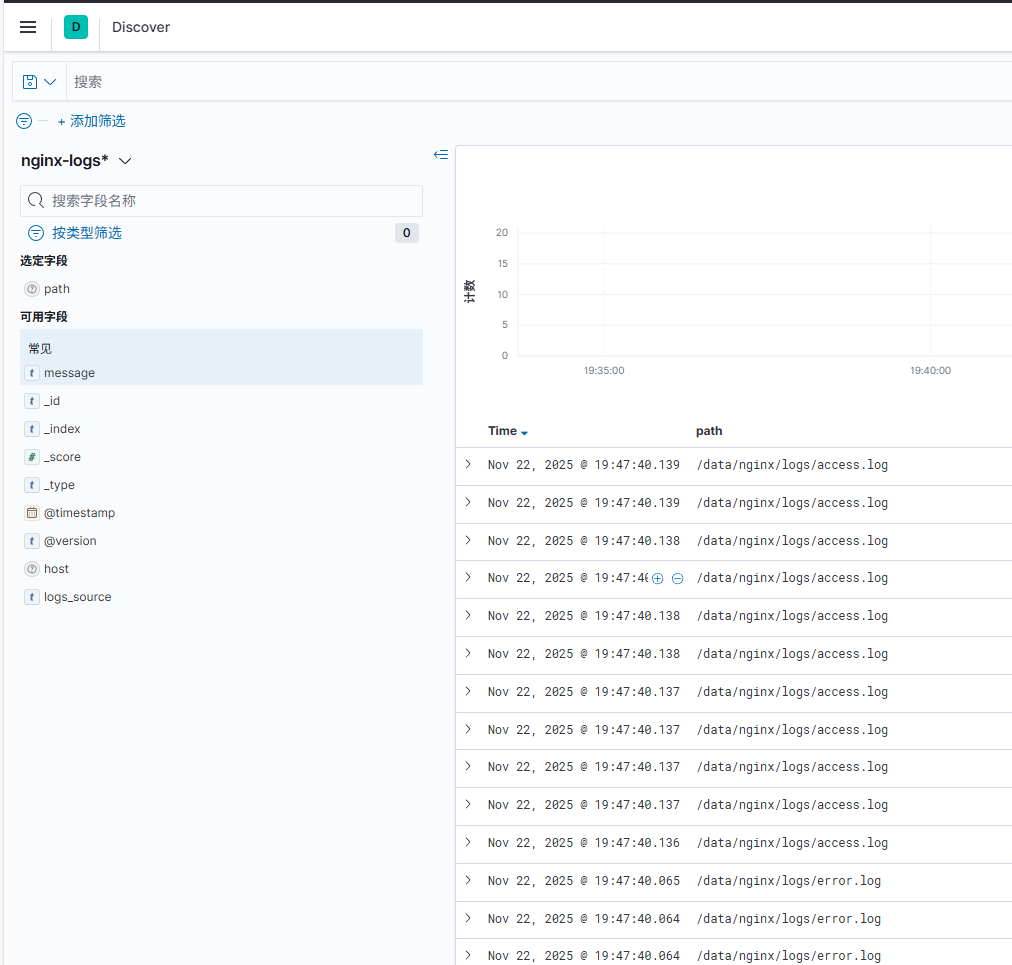
1.6 预览配置后的日志
正常预览不同服务、路径日志


2、传统elk业务场景
2.1 logstash配置
input {
#采集nginx日志
file {
path => "/data/nginx/logs/*.log"
start_position => "beginning"
#建议开启sincedb,默认的sincedb路径可能删除索引无法恢复索引,手动配置可解决这个问题,也保证了日志采集的连续性和不重不漏,这里配置.nginx
sincedb_path=> "/data/logstash/data/plugins/inputs/file/.nginx"
add_field => {
#新增logs_source字段,用于生成nginx对应的索引
"logs_source" => "nginx"
}
}
#采集backend日志
file {
path => "/data/logs/*/*.log"
start_position => "beginning"
#建议开启sincedb,默认的sincedb路径可能删除索引无法恢复索引,手动配置可解决这个问题,也保证了日志采集的连续性和不重不漏,这里配置.backend
sincedb_path=> "/data/logstash/data/plugins/inputs/file/.backend"
add_field => {
#新增logs_source字段,用于生成backend对应的索引
"logs_source" => "backend"
}
}
}
filter {
#判断Nginx日志来源
if [logs_source] == "nginx" {
grok {
#贪婪匹配原则,仅演示,按日志需求配置正则
match => { "message" => '%{GREEDYDATA}' }
}
}
#判断后端日志来源
else if [logs_source] == "backend" {
#多后端业务日志核心配置,用于识别不同子路径的服务名和文件名
dissect {
mapping => {
#匹配好路径,映射到logstash的默认字段path
"path" => "/data/logs/%{service_name}/%{file_name}"
}
}
grok {
#贪婪匹配原则,仅演示,按日志需求配置正则
match => { "message" => '%{GREEDYDATA}' }
}
}
}
#输出数据到es
output {
elasticsearch {
hosts => ["http://172.16.10.132:9200"]
#logs_source变量,会根据消费kafka的字段生成对应的索引,如nginx-logs-2025.11.22和backend-logs-2025.11.22
index => "%{logs_source}-logs-%{+YYYY.MM.dd}"
user => "elastic"
password => "xxxxxx"
}
}
2.2 重启logstash
/data/logstash/bin/logstash -f /data/logstash/config/logstash.conf
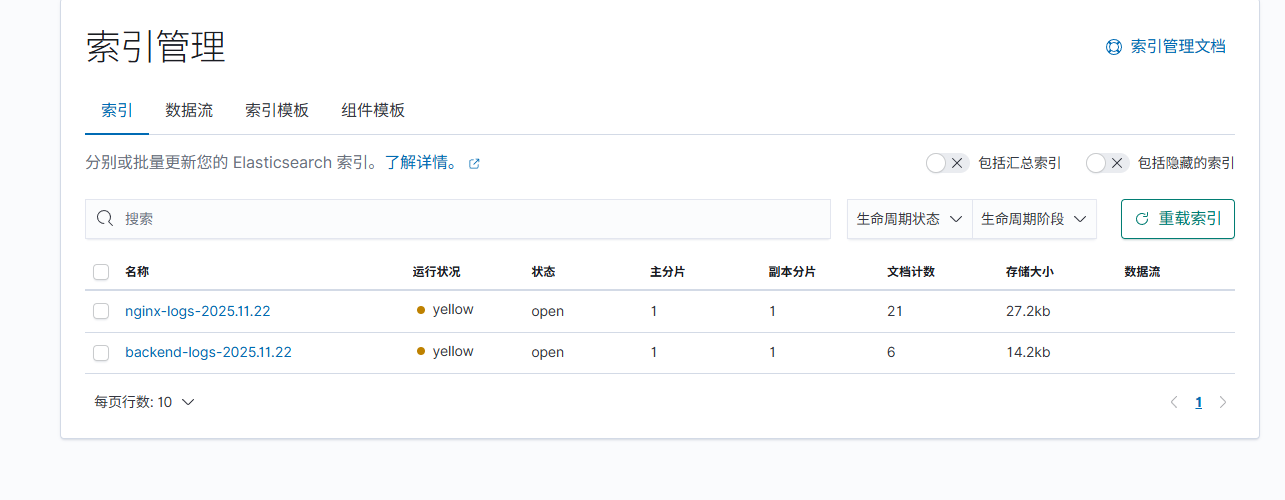
2.3 检查索引
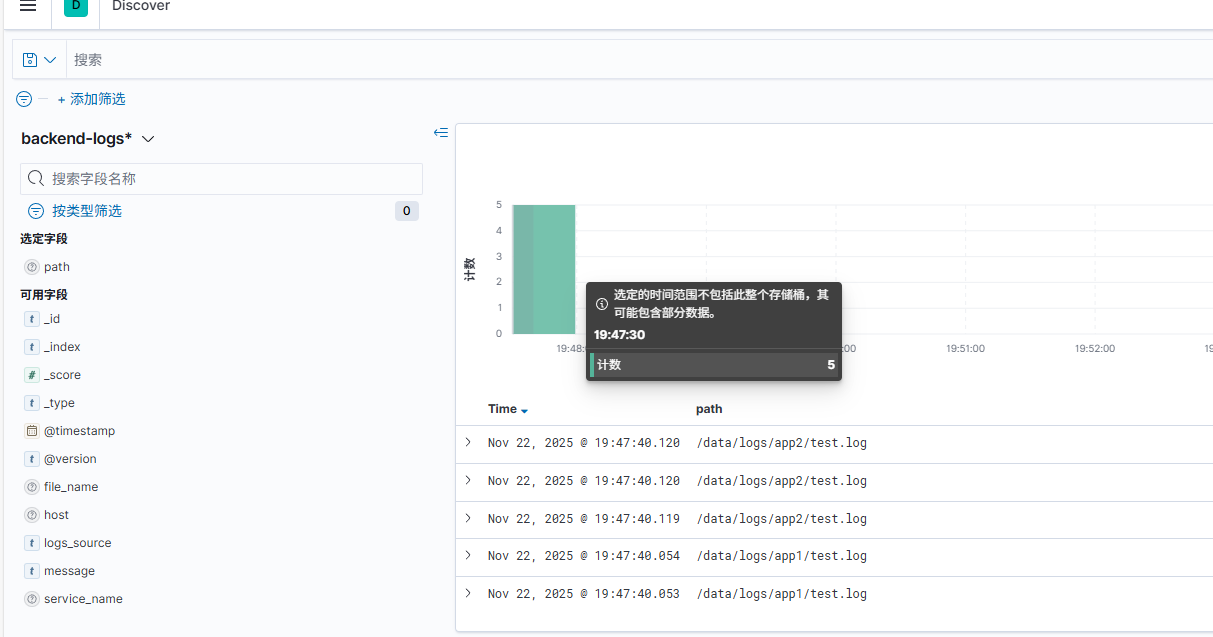
2.4 预览配置后的日志
因仅演示,未作grok表达式,字段较集中


评论区