

一、准备虚拟机环境
| 主机名 | 操作系统 | 配置 | 角色 |
|---|---|---|---|
| 172.16.10.128 | CentOS 7.9 | 2c2g 40G | master1 |
| 172.16.10.129 | CentOS 7.9 | 2c2g 40G | master2 |
| 172.16.10.130 | CentOS 7.9 | 2c4g 60G | node1 |
| 172.16.10.131 | CentOS 7.9 | 2c4g 60G | node2 |
二、前置条件
2.1 环境准备
-
操作系统:所有节点统一使用
CentOS 7.9+,内核版本3.10+(CentOS)。 -
网络要求:
- 所有节点间网络互通(含端口开放,见下表)。
- DNS 能解析公网(用于下载组件),或配置离线镜像仓库。
-
时间同步:所有节点安装
ntpd或chronyd,确保时间偏差 < 30秒。# CentOS yum install -y chrony && systemctl enable --now chronyd#配置阿里时钟源,vim /etc/chrony.conf,加入以下源,然后systemctl restart chronyd server 0.cn.pool.ntp.org iburst -
关闭Swap:所有节点永久关闭Swap分区(Kubernetes 要求)。
swapoff -a && sed -i '/swap/s/^/#/' /etc/fstab -
禁用SELinux(CentOS):
setenforce 0 && sed -i 's/^SELINUX=.*/SELINUX=permissive/' /etc/selinux/config -
关闭防火墙
systemctl stop firewalld && systemctl disable firewalld
2.2 开放端口清单
| 组件/服务 | 端口/协议 | 方向 | 说明 |
|---|---|---|---|
| kube-apiserver | 6443/TCP | 所有节点 → Master | API 入口(通过VIP) |
| etcd | 2379-2380/TCP | Master 互访 | etcd 客户端/服务端通信 |
| kubelet | 10250/TCP | Master → Node | kubelet API |
| kube-scheduler | 10259/TCP | Master 互访 | 调度器健康检查 |
| kube-controller | 10257/TCP | Master 互访 | 控制器管理器健康检查 |
| Keepalived | 112/VRRP | Master 互访 | VRRP 协议(组播) |
| Haproxy | 8404/TCP | Master 互访 | Haproxy 健康检查 |
| 容器网络(Calico) | 179/TCP(BGP) | 所有节点互访 | Calico 网络通信(可选) |
三、安装Docker(所有节点)
3.1 安装Docker Engine
# CentOS
yum install -y yum-utils
yum-config-manager --add-repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
yum install -y docker-ce docker-ce-cli containerd.io
3.2 配置Docker
- 设置国内镜像加速(可选):
#cgroup驱动为systemd mkdir -p /etc/docker cat > /etc/docker/daemon.json <<EOF { "registry-mirrors": ["https://registry.cn-hangzhou.aliyuncs.com"], "exec-opts": ["native.cgroupdriver=systemd"], "log-driver": "json-file", "log-opts": { "max-size": "100m" } } EOF - 启动Docker
systemctl enable --now docker
四、安装cri-dockerd(适配K8s 1.24+)
背景:K8s 1.24+ 移除了对Docker的直接支持,需通过
cri-dockerd桥接CRI与Docker。
4.1 下载并安装cri-dockerd
# 下载二进制(以v0.4.0为例,匹配K8s 1.28)
wget https://github.com/Mirantis/cri-dockerd/releases/download/v0.4.0/cri-dockerd-0.4.0.amd64.tgz
tar zxvf cri-dockerd-0.4.0.amd64.tgz
mv cri-dockerd/cri-dockerd /usr/local/bin/
# 配置服务文件
cat > /etc/systemd/system/cri-docker.service <<EOF
[Unit]
Description=CRI Interface for Docker Application Container Engine
Documentation=https://docs.mirantis.com
After=network-online.target docker.service
Requires=docker.service
[Service]
Type=notify
ExecStart=/usr/local/bin/cri-dockerd \
--network-plugin=cni \
--cni-conf-dir=/etc/cni/net.d \
--pod-infra-container-image=registry.aliyuncs.com/google_containers/pause:3.9 \
--container-runtime-endpoint=unix:///run/cri-dockerd.sock
ExecReload=/bin/kill -s HUP $MAINPID
TimeoutSec=0
RestartSec=2
Restart=always
[Install]
WantedBy=multi-user.target
EOF
# 启动服务并验证
systemctl daemon-reload
systemctl enable cri-docker --now
systemctl status cri-docker # 确保状态为active
五、安装Kubernetes组件(所有节点)
5.1 配置K8s源
cat > /etc/yum.repos.d/kubernetes.repo <<EOF
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes-new/core/stable/v1.28/rpm/
enabled=1
gpgcheck=1
gpgkey=https://mirrors.aliyun.com/kubernetes-new/core/stable/v1.28/rpm/repodata/repomd.xml.key
EOF
5.2 安装kubeadm、kubelet、kubectl
# 安装指定版本(此处为v1.28.2)
yum install -y kubeadm-1.28.2 kubelet-1.28.2 kubectl-1.28.2 --disableexcludes=kubernetes
# 启动kubelet(预启动,由kubeadm触发完整配置)
systemctl enable kubelet
六、部署高可用Master集群
6.1 部署Haproxy+Keepalived(双Master节点)
6.1.1 安装Haproxy(所有Master节点)
yum install -y haproxy
# 配置haproxy.cfg(修改所有Master节点)
cat > /etc/haproxy/haproxy.cfg <<EOF
global
log /dev/log local0
log /dev/log local1 notice
chroot /var/lib/haproxy
stats socket /run/haproxy/admin.sock mode 660 level admin
stats timeout 30s
user haproxy
group haproxy
daemon
defaults
log global
mode tcp
option tcplog
option dontlognull
retries 3
timeout connect 5000
timeout client 50000
timeout server 50000
frontend k8s-api
#端口不能和6443冲突
bind *:8443
mode tcp
default_backend k8s-api-backend
backend k8s-api-backend
mode tcp
balance roundrobin
#apiserver的端口
server master-01 172.16.10.128:6443 check inter 2000 fall 3
server master-02 172.16.10.129:6443 check inter 2000 fall 3
listen stats
bind *:8404
mode http
stats enable
stats uri /haproxy?stats
EOF
# 启动Haproxy
mkdir -p /run/haproxy
systemctl enable --now haproxy
6.1.2 安装Keepalived(所有Master节点)
# CentOS
yum install -y keepalived
# 配置keepalived.conf(master1示例,master2调整priority为90)
cat > /etc/keepalived/keepalived.conf <<EOF
global_defs {
router_id LVS_DEVEL
}
vrrp_script check_haproxy {
script "pidof haproxy"
interval 2
weight 2
}
vrrp_instance VI_1 {
# master2改为BACKUP
state MASTER
# 替换为实际网卡名(如ens32)
interface ens32
virtual_router_id 51
# master2改为90
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
# 自定义同网段VIP地址
172.16.10.132/24
}
track_script {
check_haproxy
}
}
EOF
# 启动Keepalived
systemctl enable --now keepalived
6.2 初始化第一个Master节点(master1)
6.2.1 编写kubeadm配置文件
#master1先写入文件,不执行
cat > kubeadm-config.yaml <<EOF
apiVersion: kubeadm.k8s.io/v1beta3
kind: ClusterConfiguration
imageRepository: registry.aliyuncs.com/google_containers
kubernetesVersion: v1.28.2
controlPlaneEndpoint: "172.16.10.132:8443"
networking:
podSubnet: "10.244.0.0/16"
etcd:
local:
dataDir: /var/lib/etcd
---
apiVersion: kubelet.config.k8s.io/v1beta1
kind: KubeletConfiguration
cgroupDriver: systemd
---
apiVersion: kubeadm.k8s.io/v1beta3
kind: InitConfiguration
nodeRegistration:
criSocket: unix:///run/cri-dockerd.sock
EOF
6.2.2 执行初始化
#master1执行拉取镜像
# 拉取阿里源代理Kubernetes 核心组件
docker pull registry.aliyuncs.com/google_containers/kube-apiserver:v1.28.2
docker pull registry.aliyuncs.com/google_containers/kube-controller-manager:v1.28.2
docker pull registry.aliyuncs.com/google_containers/kube-scheduler:v1.28.2
docker pull registry.aliyuncs.com/google_containers/kube-proxy:v1.28.2
# 拉取 etcd
docker pull registry.aliyuncs.com/google_containers/etcd:3.5.9-0
# 拉取 CoreDNS
docker pull registry.aliyuncs.com/google_containers/coredns:v1.10.1
# 拉取 pause 容器
docker pull registry.aliyuncs.com/google_containers/pause:3.9
#拉取calico网络插件镜像,镜像版本可能会改变,但目前适用,假如不适用,拉取新版本即可
docker pull dockerproxy.net/calico/kube-controllers:v3.25.0
docker pull dockerproxy.net/calico/cni:v3.25.0
docker pull dockerproxy.net/calico/node:v3.25.0
#假如上述dockerproxy.net不可使用,可用以下quay.io地址,更推荐!!!!
docker pull quay.io/calico/kube-controllers:v3.25.0
docker pull quay.io/calico/cni:v3.25.0
docker pull quay.io/calico/node:v3.25.0
#master1初始化集群
kubeadm init --config kubeadm-config.yaml --upload-certs
# 成功后记录join命令(后续用于添加Master和Node)
# 示例输出:
kubeadm join 172.16.10.132:8443 --token 9ietxf.dk8i39q4753xhjrq --discovery-token-ca-cert-hash sha256:eeb0305d777803d90c412a7cd8f522212c15cba134106788b8397d8003e8b99a --certificate-key 51fd934298886a61385d937d4c9c72f70687f6eb56a48beb63589fcc7f452437 --cri-socket unix:///run/cri-dockerd.sock
6.2.3 配置kubectl(master1)
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
6.2.4 向各节点推送所需镜像
目的是为了快速部署,省去各节点重新从互联网拉取镜像
#master1执行
docker save -o kube-apiserver.tar registry.aliyuncs.com/google_containers/kube-apiserver:v1.28.2
docker save -o kube-controller-manager.tar registry.aliyuncs.com/google_containers/kube-controller-manager:v1.28.2
docker save -o kube-scheduler.tar registry.aliyuncs.com/google_containers/kube-scheduler:v1.28.2
docker save -o kube-proxy.tar registry.aliyuncs.com/google_containers/kube-proxy:v1.28.2
docker save -o etcd.tar registry.aliyuncs.com/google_containers/etcd:3.5.9-0
docker save -o coredns.tar registry.aliyuncs.com/google_containers/coredns:v1.10.1
docker save -o pause.tar registry.aliyuncs.com/google_containers/pause:3.9
docker save -o kube-controllers.tar quay.io/calico/kube-controllers:v3.25.0
docker save -o cni.tar quay.io/calico/cni:v3.25.0
docker save -o node.tar quay.io/calico/node:v3.25.0
#可提前做机器免密,免去scp过程中输入密码的操作,详情不再赘述,可自行百度
#master1发送镜像到master2,假设保存镜像路径为/root,则cd /root,需传全部镜像
for i in `ls |grep tar`;do scp $i root@172.16.10.129:/root ;done
#master1发送镜像到node1和node2,假设保存镜像路径为/root,则cd /root,需传全部镜像
scp kube-proxy.tar root@172.16.10.130:/root
scp cni.tar root@172.16.10.130:/root
scp node.tar root@172.16.10.130:/root
scp pause.tar root@172.16.10.130:/root
scp kube-proxy.tar root@172.16.10.131:/root
scp cni.tar root@172.16.10.131:/root
scp node.tar root@172.16.10.131:/root
scp pause.tar root@172.16.10.131:/root
#master2、node1、node2接收到到/root下的镜像,提前导入到docker
cd /root
for i in `ls |grep tar`;do docker load -i $i ;done
#随后会导入各对应docker
6.3 添加第二个Master节点(master2)
使用master1初始化后输出的 kubeadm join 命令(需包含 --control-plane 参数):
kubeadm join 172.16.10.132:8443 --token umowq3.7n7w33lb1yui3x8f \
--discovery-token-ca-cert-hash sha256:8c9df9ebef026dc4590ca78ac29b91614ad1fcc91bdbca491d9fc4565bca4294 \
--control-plane --certificate-key c8aefaa45cbbbff019b32e8df30826c959c2d9a3bcb79d25f28ca0cbbe4363f8 \
--cri-socket unix:///run/cri-dockerd.sock
# 验证Master节点状态(在任意Master节点执行)
kubectl get nodes
七、部署Node节点
7.1 加入集群(node1/node2)
使用master1初始化时生成的Node节点join命令(不带 --control-plane 参数):
kubeadm join 172.16.10.132:8443 --token umowq3.7n7w33lb1yui3x8f \
--discovery-token-ca-cert-hash sha256:8c9df9ebef026dc4590ca78ac29b91614ad1fcc91bdbca491d9fc4565bca4294 \
--cri-socket unix:///run/cri-dockerd.sock
7.2 安装网络插件(Calico)
在任意Master节点执行
wget https://docs.projectcalico.org/manifests/calico.yaml
sed -i 's|docker.io/|quay.io/|g' calico.yaml
kubectl apply -f calico.yaml
八、集群验证
8.1 检查节点状态
kubectl get nodes -o wide
# 预期所有节点STATUS为Ready
8.2 检查组件状态
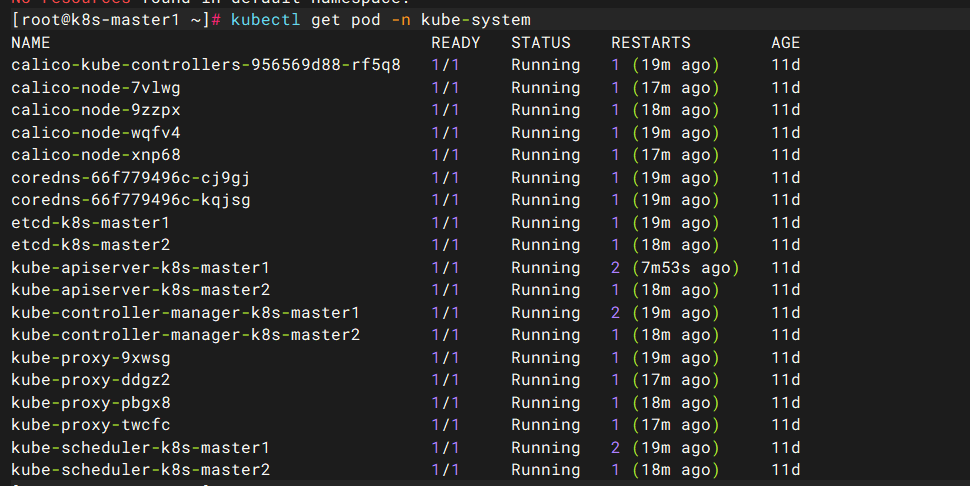
kubectl get pod -n kube-system
# 确保etcd、kube-apiserver、kube-controller-manager、kube-scheduler、calico等组件Running
8.3 验证高可用性
- 模拟master1故障(关机或停止kube-apiserver)。
- 检查VIP是否漂移到master2(
ip addr show ens32查看是否包含172.16.10.132)。 - 执行
kubectl get nodes确认仍可连接API Server。
九、维护注意事项
- 升级集群:按顺序升级Master节点(先升级非当前VIP节点),使用
kubeadm upgrade命令。 - ETCD备份:定期备份
/var/lib/etcd目录,或使用etcdctl snapshot save命令。 - Docker版本兼容:K8s与Docker的版本需通过
cri-dockerd匹配,升级时需验证兼容性。 - 节点维护:对节点执行维护前,使用
kubectl cordon标记为不可调度,kubectl drain迁移Pod。
十、QA
Q:虚拟机迁移,可能无法启动k8s服务器?
A:也许遇到了cpu状态不一致,关闭或取消虚拟机状态,重新开机即可运行虚拟机
Q:k8s集群无法启动
A1:首先检查kubelet是否正常
systemctl status kubelet
A2:检查docker、cri-docker
systemctl start docker && systemctl start cro-docker
Q:容器全部启动好了,但是kubectl get nodes报错
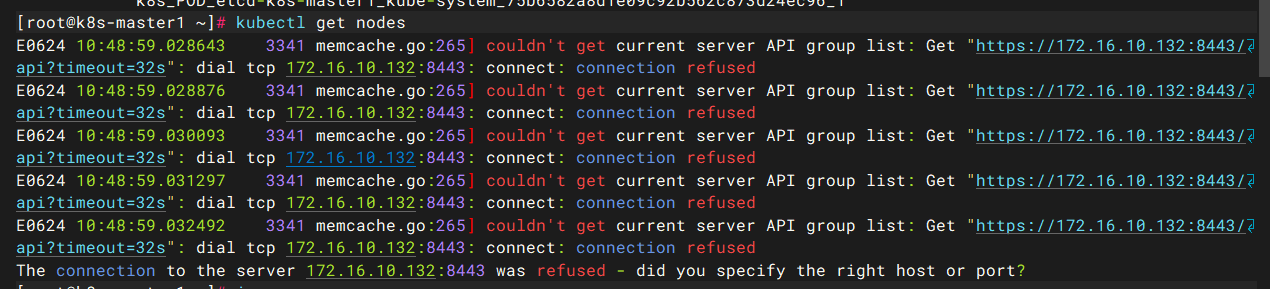
A:看图是未连接8443端口,正常情况下api-server的安全端口是6443,8443可能是设置的高可用端口,由此可以定位到keepalived和haproxy或其他负载均衡组件
systemctl status keepalived && systemctl status haproxy
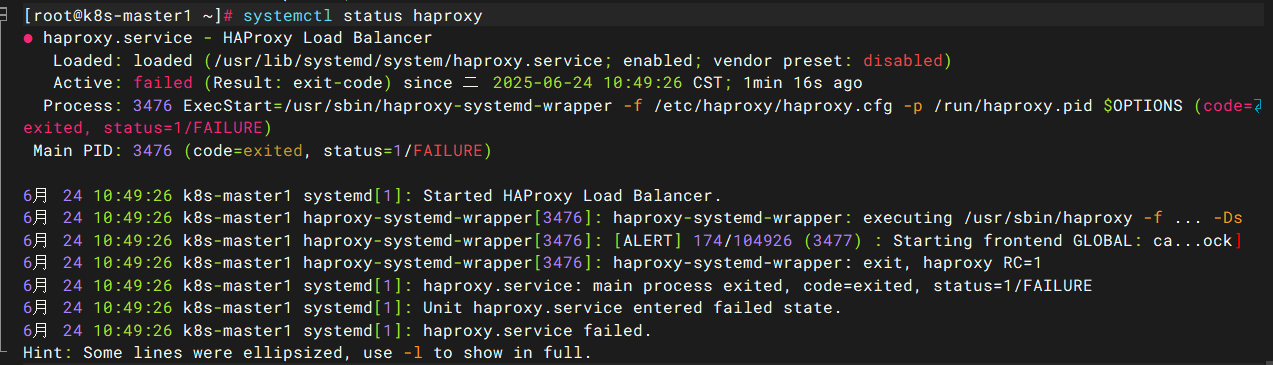
检查发现是haproxy未启动,可以加入-l 参数检查报错,systemctl status haproxy -l
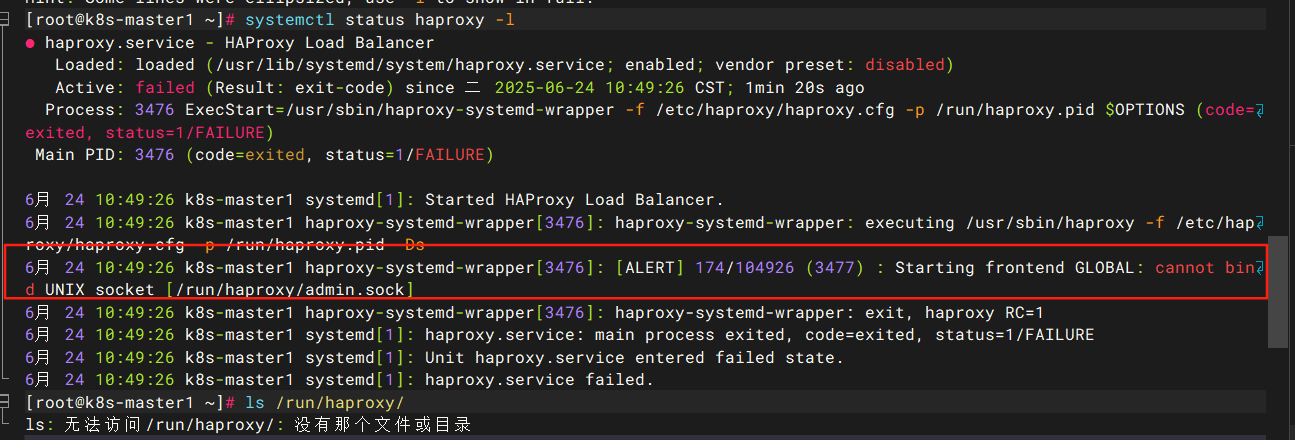
检查到突破口,无法创建admin.sock套接字,可能是虚拟机迁移导致状态丢失,重建一个/run/haproxy目录即可
mkdir -p /run/haproxy && systemctl start haproxy
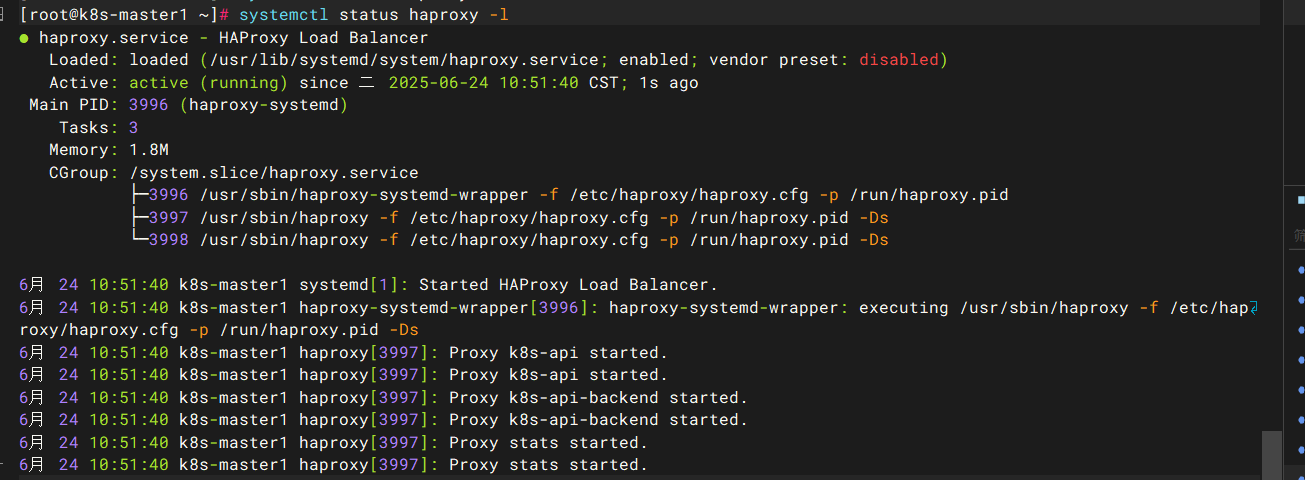
此时haproxy状态已经正常,k8s-apiserver已经可以正常负载,k8s集群应该是可以恢复到正常状态
kubectl get nodes -o wide

kubectl get pod -n kube-system


评论区