

1、需求背景
2、过滤器
1、使用grok过滤器:因为日志行由固定的分隔符
|分割,grok 是基于正则表达式的,匹配灵活度较高。2、使用 mutate过滤器:进行字段重命名、数据类型转换(如将状态码 "200" 转为整数 200)和清理无用字段。
3、全字段配置
3.1 grok表达式
时间戳
2025-11-14 13:48:32.835是一个标准的 ISO8601 时间戳格式,grok内置
#表达式:%{TIMESTAMP_ISO8601}
分隔符|
#表达式: \s*\|\s*
\s* 匹配0个或多个空白字符
\\| 为|本身,\作为转义符
日志级别
INFO日志级别,内置模式LOGLEVEL
#表达式 %{LOGLEVEL:log_level}
健壮通配正则表达式--懒惰匹配模式
(?<field1>.*?)
. :匹配除换行符以外的任意单个字符
* : 是一个量词,表示匹配前面的元素
#默认情况下 .* 代表贪婪模式,会匹配多字符
#因此.*?尽可能少匹配字符,它会首先匹配0个字符
日志消息主体
这是最灵活的部分,可能包含任何字符,包括我们用作分隔符的 |。对于最后一个字段,我们应该使用 GREEDYDATA,它会匹配行尾的所有剩余内容。
#表达式:%{GREEDYDATA:message}
#日志样例
2025-11-14 13:48:32.835|http-nio-8085-exec-30|INFO ||regexxxxxxxx|INTERFACE|fexxxxxxxxxxx|10.xx.xx.xx|yxxx|yxxxxxx|/Token|0xxxxxxxxxxxxxxxxxxx||fxxxxxxxxxxxxxxxxxxxx|1xxxxxxxxxx|PHONE|200|20|8xxxxxxxxxxxxxxxxxxxx|{"input":{"arg0":{"token":"****"}},"output":{"success":true,"code":"0000","message":"请求成功","data":{"cxxxxxxx":1,"bxxxxxxxxxxxxxx":2,"phoneNumber":"1xxxxxxxxx","uxxxxxxxxx":"1xxxxxxxxxx","sxxxx":"100xx","nationCode":"+86"}},"exxxxxxxxx":"{\"xxxxxxxx\":0,\"axxxxx\":\"gxxxxxxxxxxxx\"}"}
健壮写法,适合大多数场景
%{TIMESTAMP_ISO8601:log_date}\s*\|\s*(?<thread>.*?)\s*\|\s*%{LOGLEVEL:log_level}\s*\|\s*(?<test_id>.*?)\s*\|\s*(?<logger>.*?)\s*\|\s*(?<log_type>.*?)\s*\|\s*(?<host_ip>.*?)\s*\|\s*(?<remote_ip>.*?)\s*\|\s*(?<system>.*?)\s*\|\s*(?<service>.*?)\s*\|\s*(?<request_url>.*?)\s*\|\s*(?<trace_id>.*?)\s*\|\|\s*(?<id>.*?)\s*\|\s*(?<phone_number>.*?)\s*\|\s*(?<device_type>.*?)\s*\|\s*(?<request_status>.*?)\s*\|\s*(?<duration>.*?)\s*\|\s*(?<span_id>.*?)\s*\|\s*%{GREEDYDATA:msg}
严格写法,按字段内容匹配
%{TIMESTAMP_ISO8601:log_date}\s*\|\s*(?<thread>[\w\.-]+)\s*\|\s*%{LOGLEVEL:log_level}\s*\|\s*(?<test_id>[^|]*)\s*\|\s*(?<logger>[a-zA-Z0-9.:]+)\s*\|\s*(?<log_type>[a-zA-Z]+)\s*\|\s*(?<host_ip>[\w:%-]+)\s*\|\s*(?<remote_ip>[\w.-]+)\s*\|\s*(?<system>[a-z-]+)\s*\|\s*(?<service>[a-z-]+)\s*\|\s*(?<request_url>[a-zA-Z0-9/]+)\s*\|\s*(?<trace_id>[a-z0-9-]+)\s*\|\|\s*(?<id>[a-z0-9]{32})\s*\|\s*(?<phone_number>\d+)\s*\|\s*(?<device_type>[a-zA-Z]+)\s*\|\s*(?<request_status>\d+)\s*\|\s*(?<duration>\d+)\s*\|\s*(?<span_id>[a-z0-9-]+)\s*\|\s*%{GREEDYDATA:msg}
grok调试网址
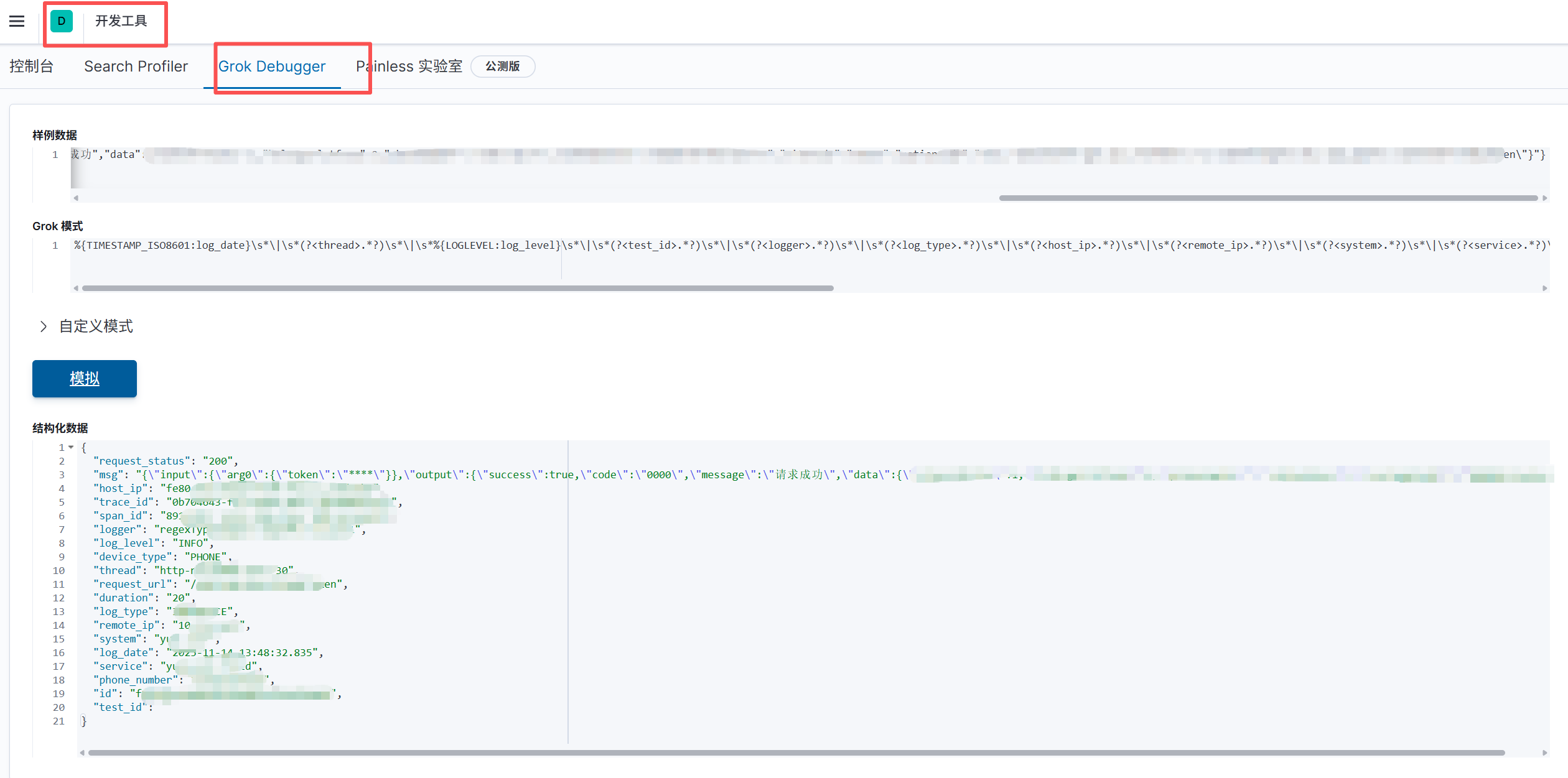
2、kibana的“开发工具”
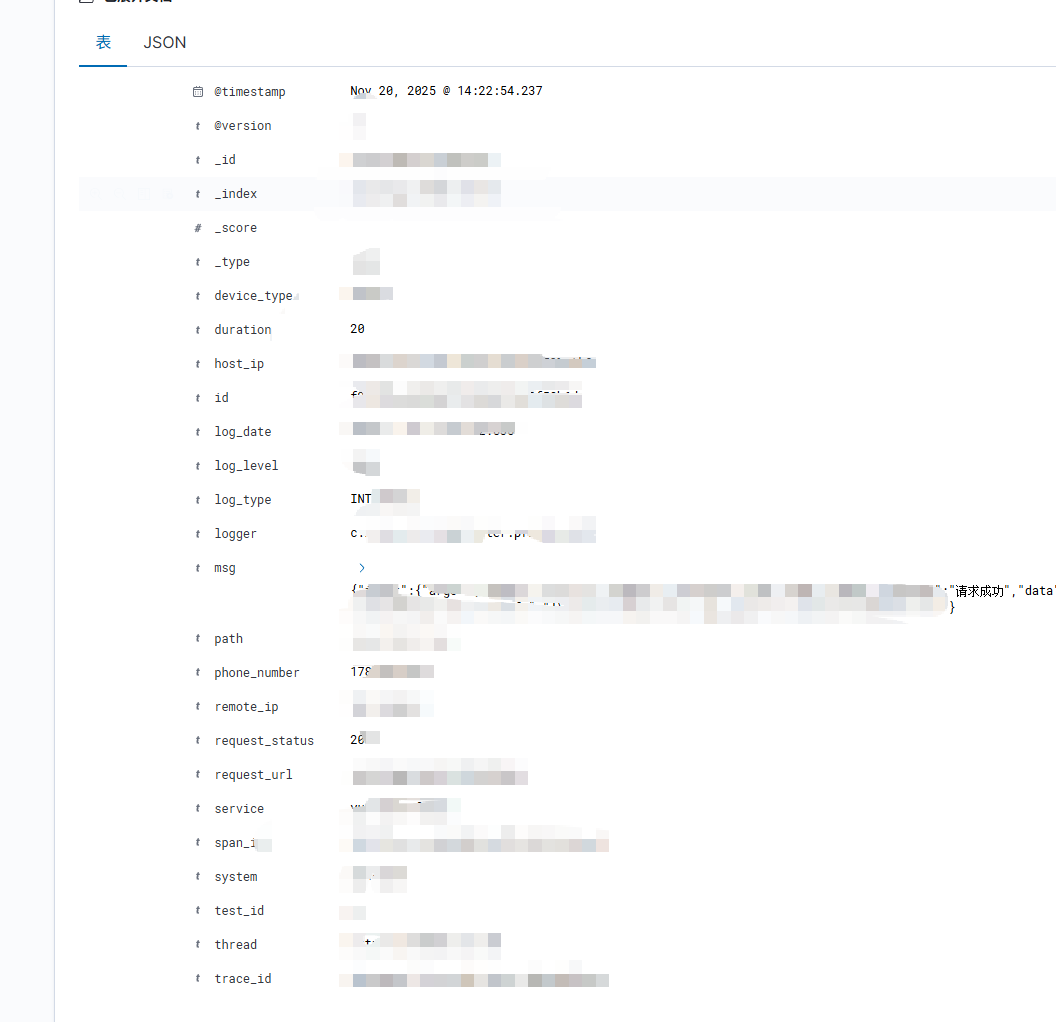
以下展示健壮表达式,由此可见,每个字段都已经被切割(用kibana开发工具调试,其他工具同理)
3.2 logstash.conf配置
input {
file {
path => ["/root/test.log"]
start_position => "beginning"
sincedb_path => "/dev/null"
}
}
filter {
grok {
match => {
"message" => '%{TIMESTAMP_ISO8601:log_date}\s*\|\s*(?<thread>.*?)\s*\|\s*%{LOGLEVEL:log_level}\s*\|\s*(?<test_id>.*?)\s*\|\s*(?<logger>.*?)\s*\|\s*(?<log_type>.*?)\s*\|\s*(?<host_ip>.*?)\s*\|\s*(?<remote_ip>.*?)\s*\|\s*(?<system>.*?)\s*\|\s*(?<service>.*?)\s*\|\s*(?<request_url>.*?)\s*\|\s*(?<trace_id>.*?)\s*\|\|\s*(?<id>.*?)\s*\|\s*(?<phone_number>.*?)\s*\|\s*(?<device_type>.*?)\s*\|\s*(?<request_status>.*?)\s*\|\s*(?<duration>.*?)\s*\|\s*(?<span_id>.*?)\s*\|\s*%{GREEDYDATA:msg}'
}
tag_on_failure => ["_grokparsefailure"]
}
}
#控制台&日志输出字段
output {
stdout {
codec => rubydebug
}
}
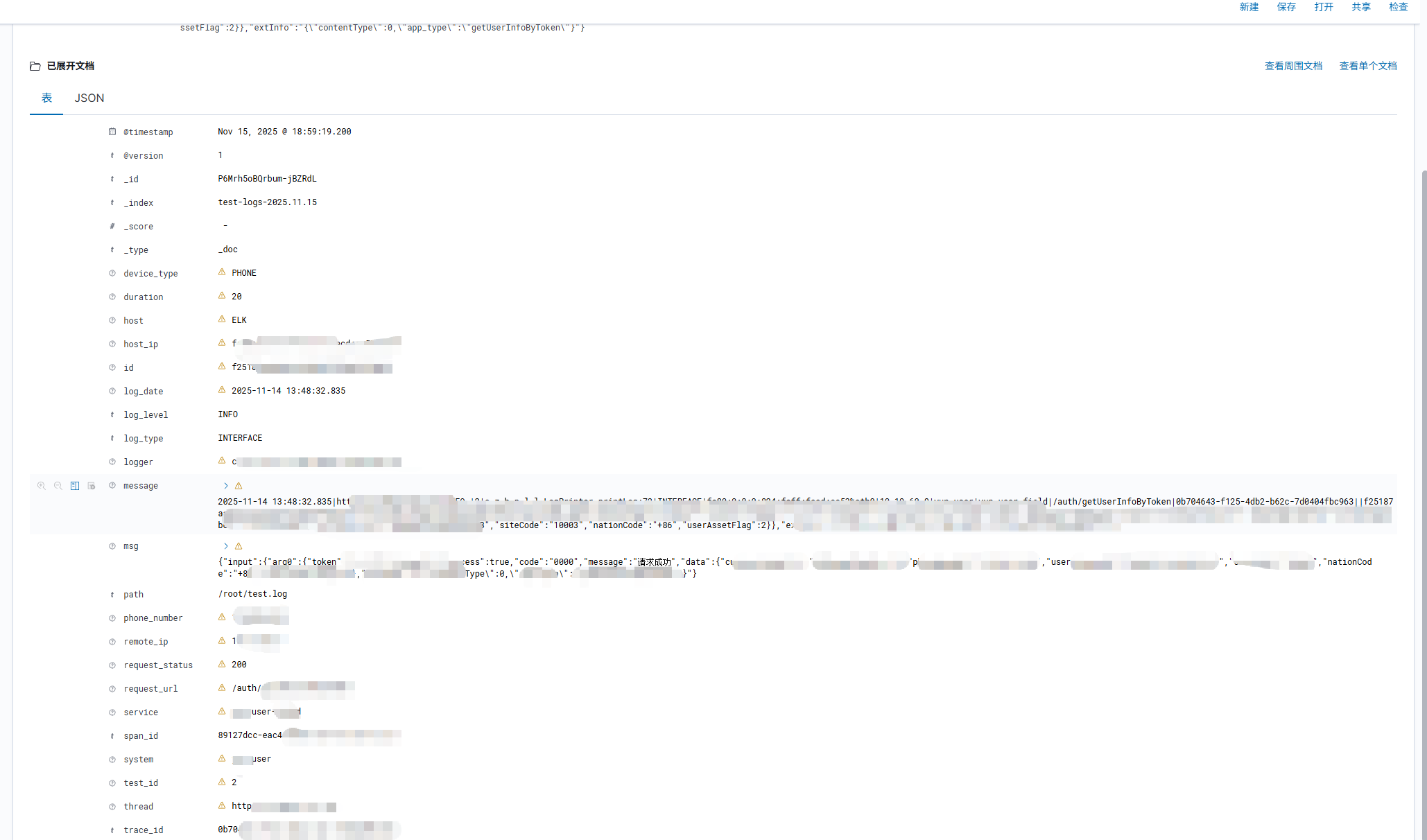
3.3 验证字段拆分
由此可见,elk上的日志字段已经被拆分
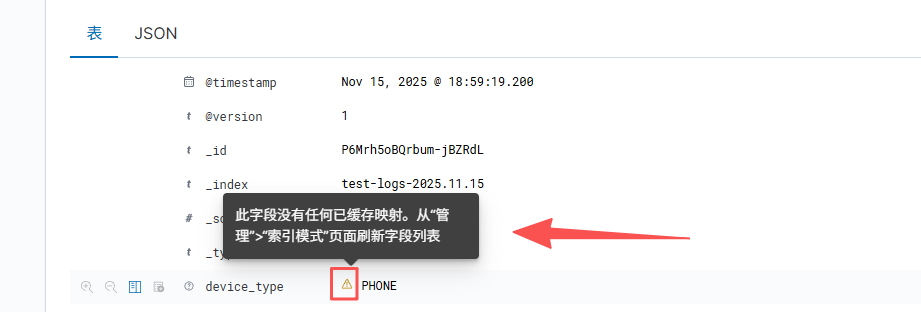
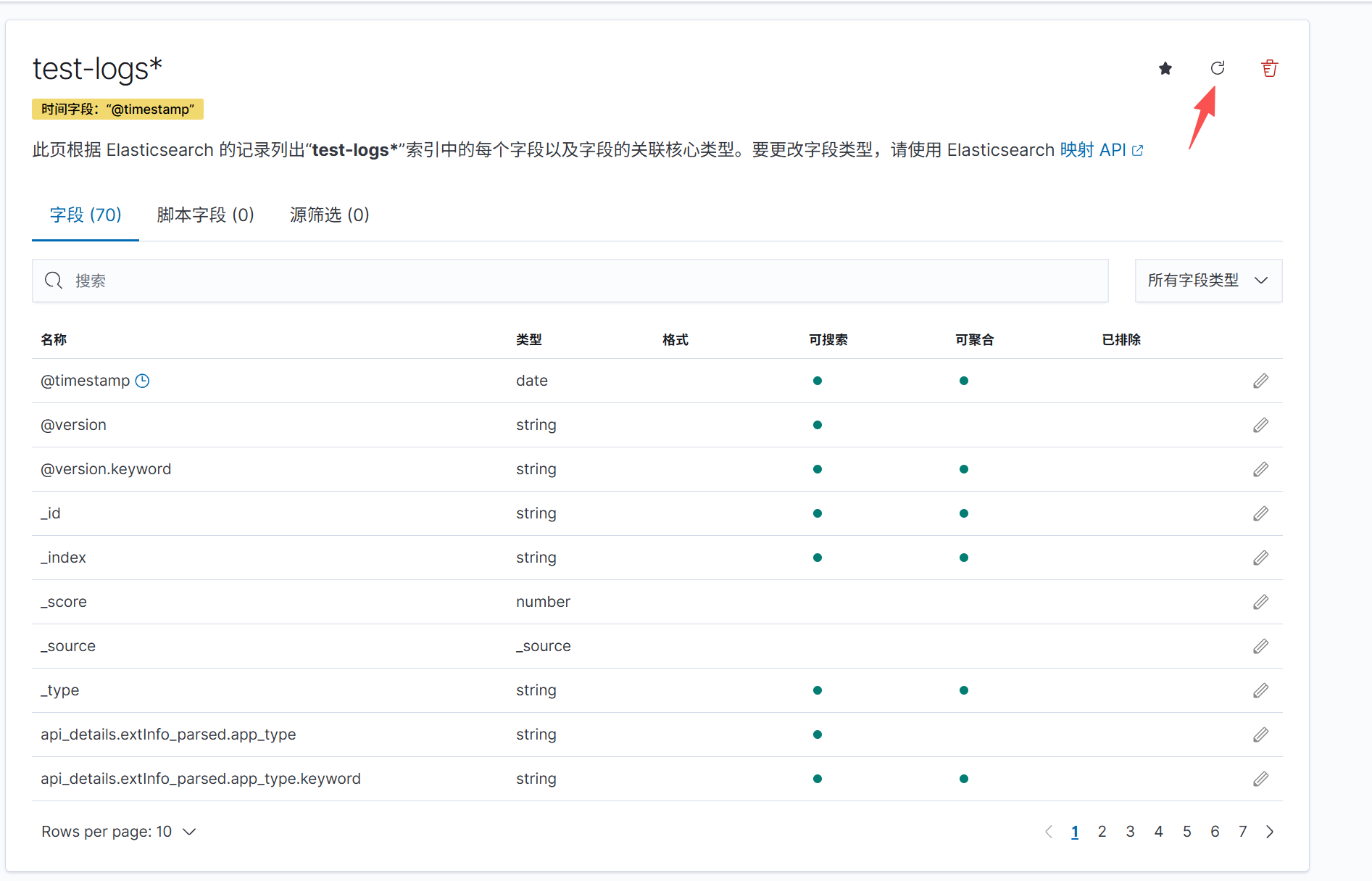
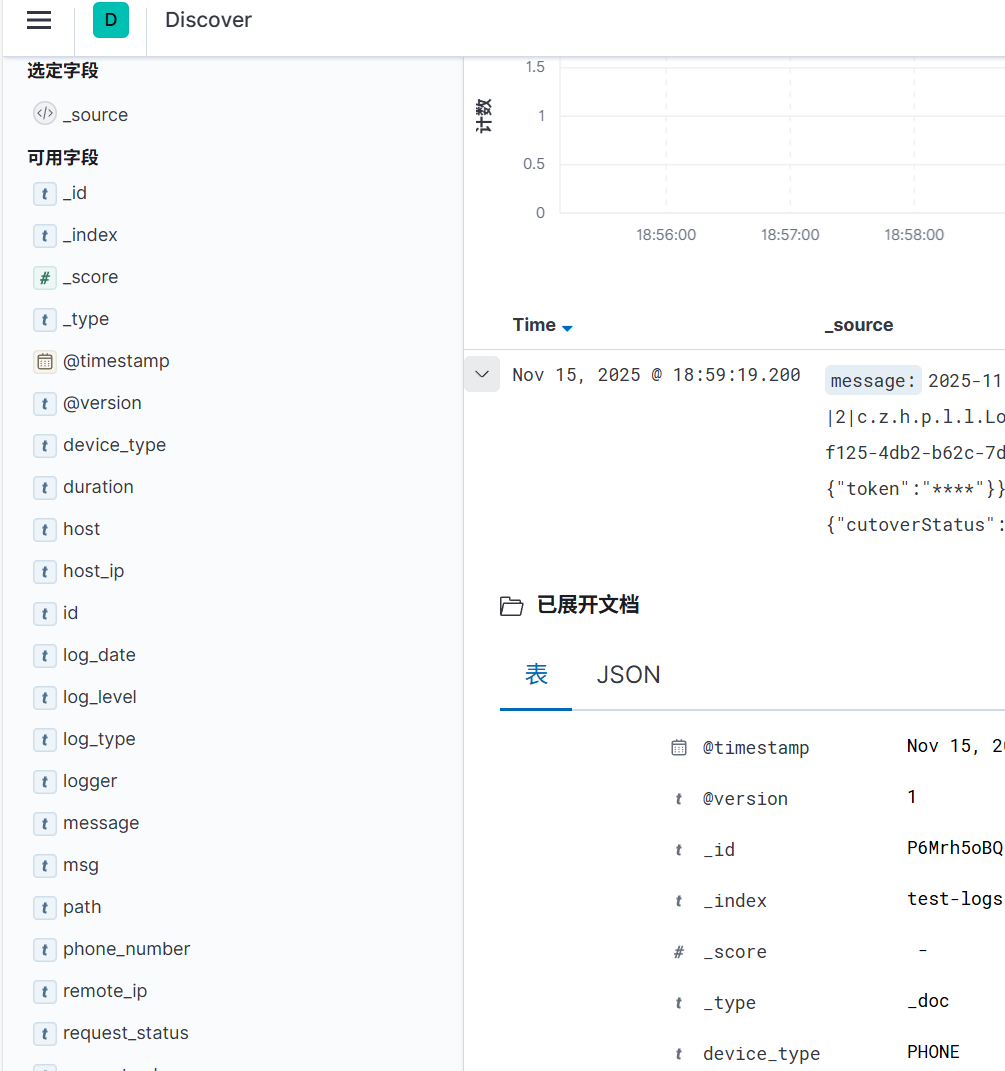
3.4 刷新字段
由于是新增的字段,kibana可能会显示警告,经过刷新字段操作即可取消警告
操作步骤

3、删除字段配置
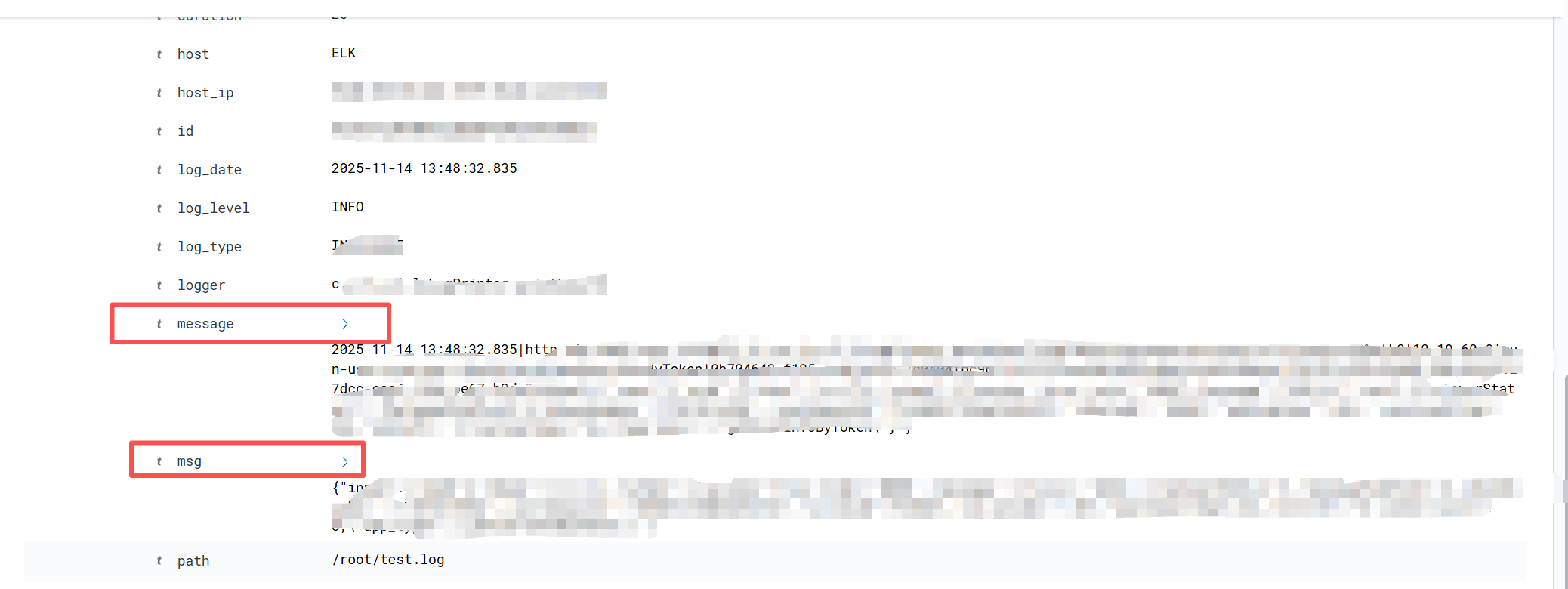
4.1 需求
message是默认的日志全部主体,而msg是自定义的msg核心主体,其他内容字段均已拆分,由此可见message字段是可删除字段,从而增加可读性。
4.2 mutate表达式
语法结构
#删除更多字段,在[]内用,分割
mutate {
remove_field => ["field1", "field2", "field3"]
}
4.3 增加logstash.conf配置
删除message字段和host集群名字段
input {
file {
path => ["/root/test.log"]
start_position => "beginning"
sincedb_path => "/dev/null"
}
}
filter {
grok {
match => {
"message" => '%{TIMESTAMP_ISO8601:log_date}\s*\|\s*(?<thread>.*?)\s*\|\s*%{LOGLEVEL:log_level}\s*\|\s*(?<test_id>.*?)\s*\|\s*(?<logger>.*?)\s*\|\s*(?<log_type>.*?)\s*\|\s*(?<host_ip>.*?)\s*\|\s*(?<remote_ip>.*?)\s*\|\s*(?<system>.*?)\s*\|\s*(?<service>.*?)\s*\|\s*(?<request_url>.*?)\s*\|\s*(?<trace_id>.*?)\s*\|\|\s*(?<id>.*?)\s*\|\s*(?<phone_number>.*?)\s*\|\s*(?<device_type>.*?)\s*\|\s*(?<request_status>.*?)\s*\|\s*(?<duration>.*?)\s*\|\s*(?<span_id>.*?)\s*\|\s*%{GREEDYDATA:msg}'
}
tag_on_failure => ["_grokparsefailure"]
}
#增加mutate配置
mutate {
remove_field => ["message", "host"]
}
}
output {
elasticsearch {
hosts => ["http://172.16.10.132:9200"]
index => "test-logs-%{+YYYY.MM.dd}"
user => "elastic"
password => "xxxxxx"
}
}
重启logstash
/data/logstash/bin/logstash -f /data/logstash/config/logstash.conf
4.4 验证删除字段
字段message和host已被删除
5、结语
至此,以上配置可满足一般日常业务需求,增加排查问题效率


评论区